New version relased in May 2023! Version 2.0 is now available for our users in our hosting services. You can also install the new version by going to our downloads page.
About

More and more, LCA and sustainability projects are performed in collaboration, be it
- within a company in one team, on one location
- within one company, across different departments, and potentially in various locations
- in research projects, with several collaborating entities, companies and universities and consultancies, with potential worldwide distribution
- as consultancy, in collaboration with clients who co-develop a case study.
While these layouts call for a smooth, fluent data exchange, they are also challenging: data may change in different locations simultaneously, and various, distributed life cycle models need to be synchronised – or rather, the synchronization needs to be managed, since sometimes it is good not to synchronise, but instead continue working with a local version. Since each dataset and life cycle model is carefully developed, it is essential to understand differences and changes before accepting a modified version to override an own model.
The LCA Collaboration Server, now in version 1.3, is developed to provide a solution for exactly this. It consists of a server application and additions in openLCA as LCA modeling software; both together allow a distributed, parallel collaboration for LCA and sustainability data set and model creation and management.
Features, example use cases
With the collaboration server and openLCA, users can commit, fetch and synchronize data across different potentially distributed users and servers / repositories. A user rights management system allows mixed teams and preserves sensitivity. All changes are monitored and documented; versioning allows roll-backs where necessary. A diff-tool shows differences between different versions of a data set or LCA model, and lets users decide whether to accept the change or not.
These solutions are broadly used and accepted in software code development (take github for example), but do not exist in the LCA world, although both “worlds” are comparable: in both, a model is crafted in a collaborative manner, under time pressure, where small changes can invalidate the entire development.
Github states it is a fast, flexible, and collaborative development process that lets you work on your own or with others. This was our inspiration.
There are many useful “architectures” for the collaboration server in practice. Here below two quick examples: a collaborative workgroup, and a data set publication pipeline, with contributions from various data providers and modellers.
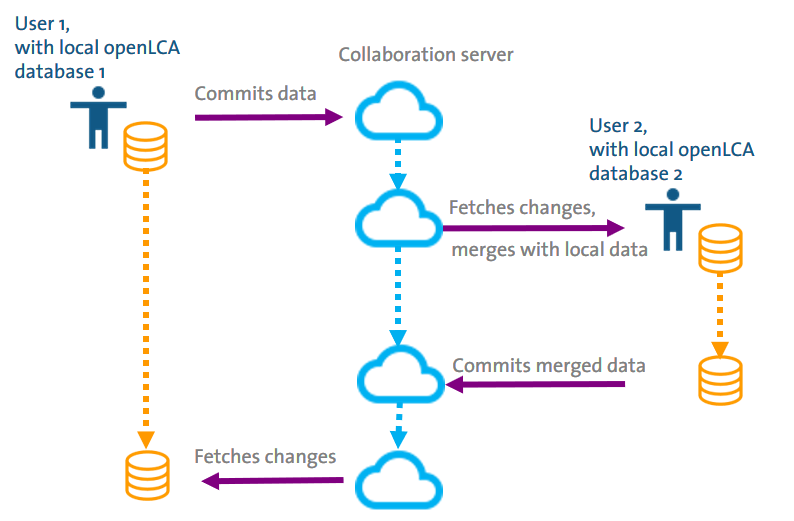
Use case – using the collaboration server in a distributed workgroup
With one central collaboration server, two or more users can use the server to synchronise their local databases; user 1 commits, user 2 fetches (downloads) the changes, compares and merges with own data, commits (submits) merged data again to the server, where user 1 can obtain the changed data.
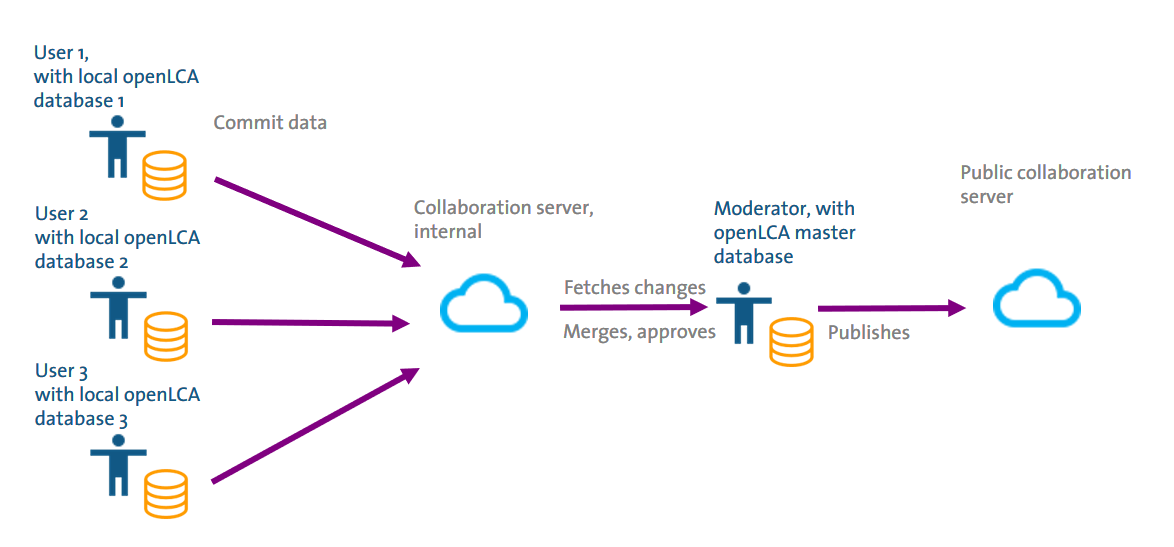
Use case – using the collaboration server in publication pipeline
In a publication pipeline, several distributed users commit data to a collaboration server, their uploads are checked and moderated, possibly against a master database, accepted submissions are merged with the master database which is then published on a public collaboration server.
Download and hosting
The LCA Collaboration Server is available for free via the download button in the top-right corner of this website. Additional hosting is offered by GreenDelta: LCA Collaboration Server – Hosting and Services.
Development
For requesting new features or reporting bugs please refer to our LCA Collaboration Server GitHub log.
Manual
For further information, you can check-out the LCA Collaboration Server Manual